
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- 백준 2512번
- java_programming
- 백준 15787번
- 모각코
- 그래프
- SWEA 15612번
- AWS
- 백준 16918번
- 백준 1987
- 알고리즘
- 백준 1331번
- MySQL
- 백준 1253번
- Python
- 백준 18310번
- 명품자바
- 백준 3085번
- 다이나믹 프로그래밍
- 그리디
- 깃헙
- 백준
- ubuntu
- 백준 17451번
- 머신러닝과 딥러닝
- 자바
- javascript
- 다이나믹프로그래밍
- SQL
- HUFS 모각코 캠프
- react
Archives
- Today
- Total
차곡차곡
[Web Crawling] it 직무 사용 기술 크롤링 본문
1. beautifulsoup 설치
pip install beautifulsoup4
2. selenium 설치
pip install -U selenium
3. pandas 설치
pip install pandas
4. Chromedriver 설치
설치 돼 있는 크롬 버전과 운영체제에 맞게 설치해야 한다.
ChromeDriver - WebDriver for Chrome - Downloads
Current Releases If you are using Chrome version 109, please download ChromeDriver 109.0.5414.25 If you are using Chrome version 108, please download ChromeDriver 108.0.5359.71 If you are using Chrome version 107, please download ChromeDriver 107.0.5304.62
chromedriver.chromium.org
5. 코드
from selenium import webdriver
from bs4 import BeautifulSoup as bs
import pandas as pd
import time
driver_path = "./chromedriver" # chromedriver 위치
url = "크롤링 할 주소"
browser = webdriver.Chrome(executable_path=driver_path)
browser.get(url) # url 주소 페이지 열기
# 스크롤 내리기
for i in range(5):
scroll_location = browser.execute_script("return document.body.scrollHeight") #스크롤 내리기 이동 전 위치
browser.execute_script("window.scrollTo(0,document.body.scrollHeight)") #현재 스크롤의 가장 아래로 내림
time.sleep(2) #전체 스크롤이 늘어날 때까지 대기
scroll_height = browser.execute_script("return document.body.scrollHeight") #늘어난 스크롤 높이
scroll_location = browser.execute_script("return document.body.scrollHeight") #늘어난 스크롤 높이
page = browser.page_source
soup = bs(page, "html.parser")
more_links = soup.find_all('div', class_ = 'Card_className__u5rsb') # class명이 'Card_className__u5rsb'인 div 태그 전체 가져옴
skill = []
for more_link in more_links:
each_more_link = "https://www.wanted.co.kr/wd/" + more_link.a['data-position-id']
browser.get(each_more_link)
info_page = browser.page_source
info_soup = bs(info_page, "html.parser")
# 기술 크롤링
skills = info_soup.find_all('div', class_ = "SkillItem_SkillItem__E2WtM")
for s in skills:
skill.append(s.string)
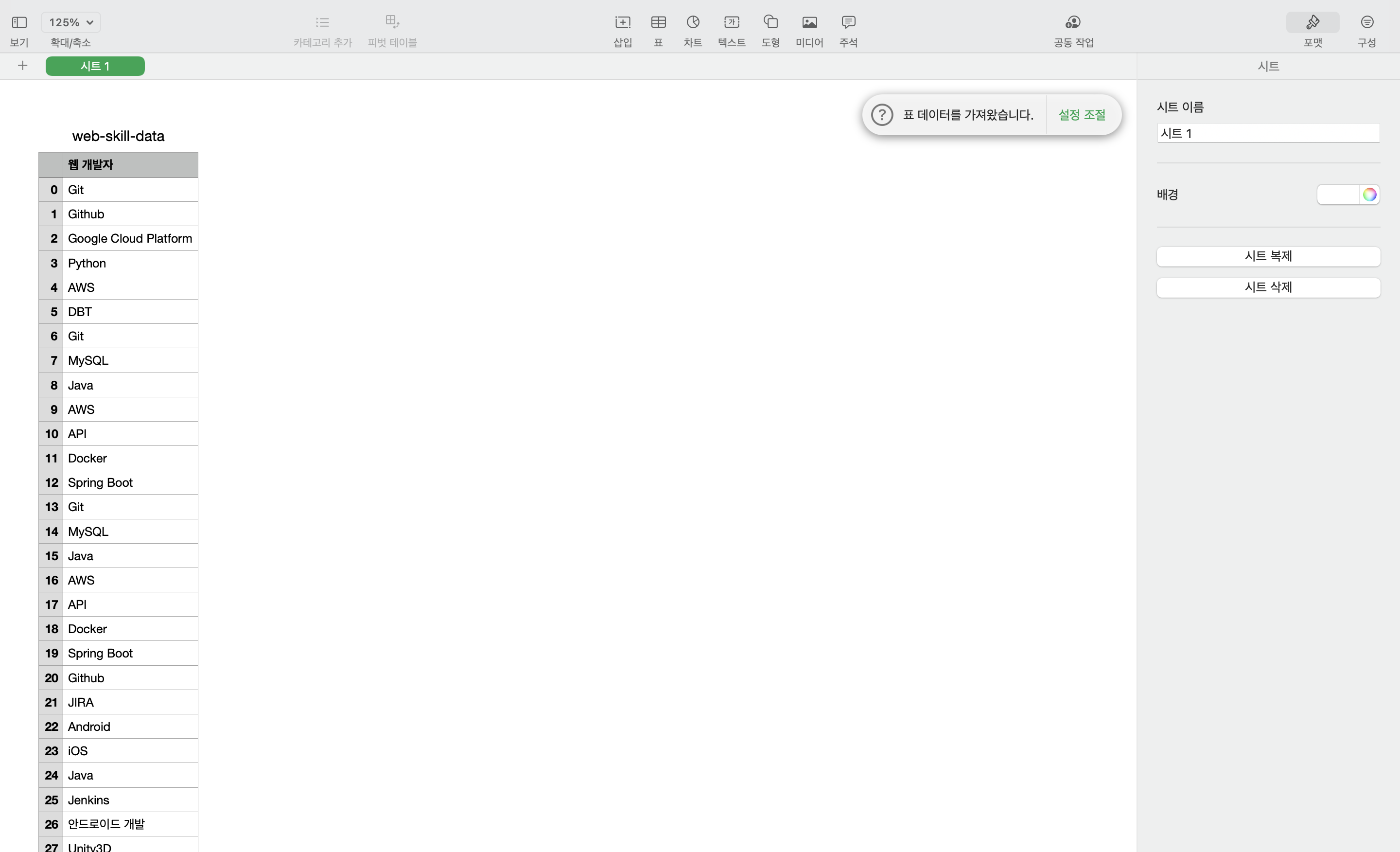
skill_df = pd.DataFrame(skill, columns=[''])
# print(skill_df)
save_frame = './app-skill-data.csv'
skill_df.to_csv(save_frame, encoding='utf-8-sig') # DataFrame csv 파일로 저장
+ 스크롤 내리기
[ep01:웹크롤링] #16 셀레니움 스크롤 조절하기 with 파이썬
[왕초보 웹크롤링 따라하기] 웹 제어, 브라우저 크기 설정, 셀레니움, Selenium, 스크롤 내리기, 스크롤 끝까지 내리기, 스크롤 위치 확인, 스크롤 단계별 내리기 업무지옥을 탈출한 건에 대하여(feat
charimlab.tistory.com
Comments