2021 데이터 청년 캠퍼스/데이터 전처리
Web page Crawling
sohy
2021. 7. 6. 00:32
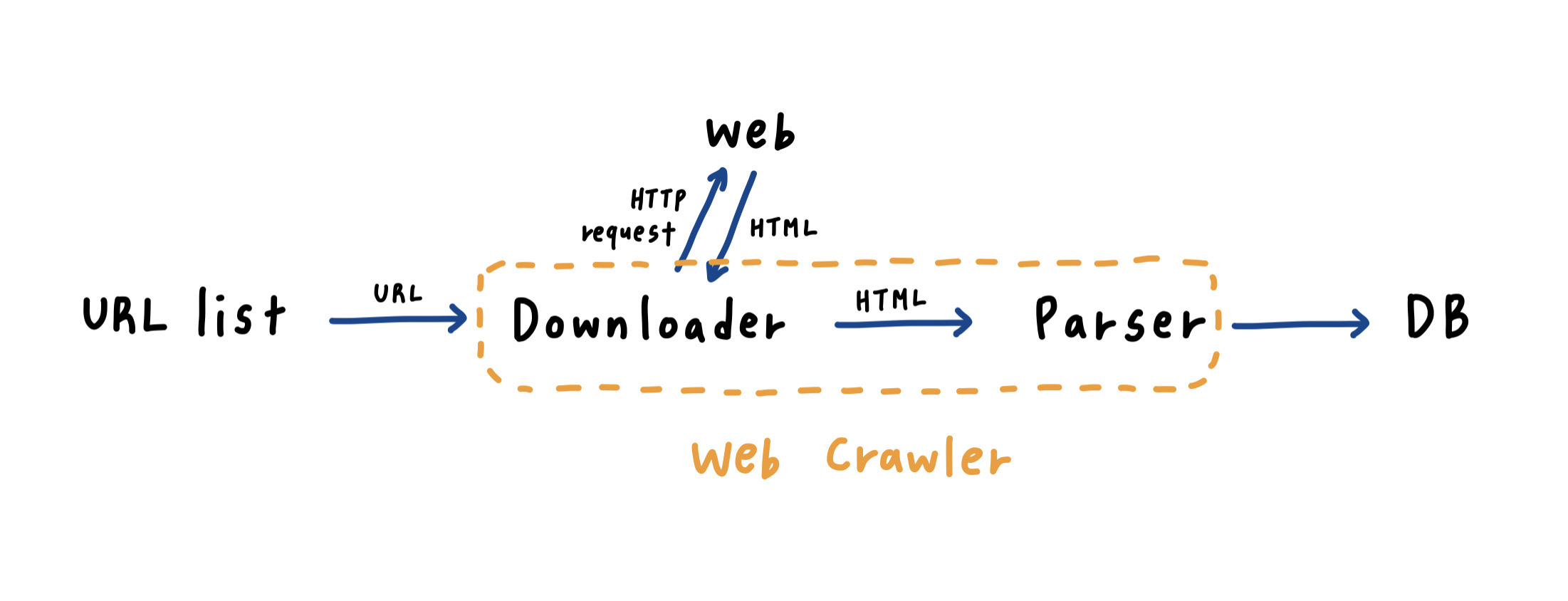
- 구글 플레이스토어에서 게일 설명 크롤링
더보기 링크 3개
for each 더보기 링크:
get 모든 게임 링크
for each 게임 링크:
description
import pandas as pd
from selenium import webdriver
from bs4 import BeautifulSoup
# parameters
driver_path = '../resources/chromedriver'
url = "https://play.google.com/store/apps/top/category/GAME"
browser = webdriver.Chrome(executable_path=driver_path) # get chromedriver
browser.get(url) # open the url
# get links of 더보기
page = browser.page_source
soup = BeautifulSoup(page, "html.parser") # get HTML text
more_links = soup.find_all('div', {'class': 'W9yFB'})
count = 0
# for each 더보기
for more_link in more_links:
each_more_link = "https://play.google.com" + more_link.a['href']
browser.get(each_more_link) # 더보기 링크 접속
each_more_page = browser.page_source
each_more_soup = BeautifulSoup(each_more_page, "html.parser")
each_more_games = each_more_soup.find_all('div', {'class': 'wXUyZd'}) # get classes (1st parsing)
game_list = []
#for every link
for game in each_more_games:
each_game_link = "https://play.google.com" + game.a['href']
browser.get(each_game_link) # 게임 링크 접속
game_info_page = browser.page_source
game_info_soup = BeautifulSoup(game_info_page, "html.parser") # get HTML text
game_title = game_info_soup.find('h1', {'class': 'AHFaub'}).text # get title
game_info_des = game_info_soup.find('div', {'jsname' : 'sngebd'}).text # get description
game_info_list = [game_title, game_info_des, each_game_link] # make a list
game_list.append(game_info_list) # append the list to empty list
game_info_df = pd.DataFrame(game_list, columns=['title', 'description', 'url']) # convert list to dataframe
save_frame = '../output/game_info_' + str(count) + '.csv'
game_info_df.to_csv(save_frame, encoding='utf-8-sig') # save the DataFrame to csv file
count += 1
[실습] 구글 플레이스토에서 게임 리뷰 크롤링
import pandas as pd
from selenium import webdriver
from bs4 import BeautifulSoup
driver_path = '../resources/chromedriver'
url = 'https://play.google.com/store/apps/top/category/GAME'
browser = webdriver.Chrome(executable_path=driver_path)
browser.get(url)
page = browser.page_source
soup = BeautifulSoup(page, "html.parser")
more_links = soup.find_all('div', {'class': 'W9yFB'})
count = 0
for more_link in more_links:
each_more_link = "https://play.google.com" + more_link.a['href']
browser.get(each_more_link)
each_more_page = browser.page_source
each_more_soup = BeautifulSoup(each_more_page, "html.parser")
each_games = each_more_soup.find_all('div', {'class': 'wXUyZd'})
game_list = []
for game in each_games:
each_game = "https://play.google.com" + game.a['href']
browser.get(each_game)
game_info_page = browser.page_source
game_info_soup = BeautifulSoup(game_info_page, "html.parser")
game_title = game_info_soup.find('h1', {'class': 'AHFaub'}).text
game_review = game_info_soup.find_all('span', {'jsname': 'bN97Pc'})
game_review_list = []
for each_game_review in game_review:
game_review_list.append(each_game_review.text)
game_info = [game_title, game_review_list]
game_list.append(game_info)
game_info_df = pd.DataFrame(game_list, columns=['title', 'review'])
save_frame = '../output/game_review_' + str(count) + '.csv'
game_info_df.to_csv(save_frame, encoding='utf-8-sig')
count += 1